因为课题的需要,需要在论文里说明清楚核间通信开销和一致性缺失事件的关系。 于是就有下面这些问题:
- 为什么会有多核,为什么CPU要向多核技术发展
- 什么是核间通信开销,核间通信和一致性缺失存在什么关系
- 核间通信开销和我们常说的多核性能以及speedup有什么关系,还和其他哪些因素有关
下面一一来看这三个问题
为什么CPU要向多核技术发展
CPU之所以要想向核心发展,是为了解决单核处理器由于主频提高而让功耗、发热量呈指数性增长的问题。我们把处理器的性能简单看做是主频和IPC的乘积,IPC全称Instruction Per Clock,即每个时钟周期内可以执行的指令数。也就是
处理器性能 = 主频 X IPC
因此,提升处理性能的途径,可以是提升主频和IPC。在十几年前,处理器的性能提升主要依赖与对主频的提高,但主频的提升并不是没有限制,看一下下面的推导:
因为:处理器功耗 跟 电流 X 电压 X 电压 X 主频 成正比,主频 跟 电压 成正比;
所以:处理器功耗 跟 主频的三次方 成正比。
也就是说,一味的提高主频,会使处理器功耗呈指数性般急剧增长,功耗过高带来的发热量问题,会严重影响使用和开发费用。于是处理器制造商开始在IPC上做功夫。
要提升IPC,可以通过提高指令执行的并行度来实现,而提高指令执行的并行度又有两个途径:一是提高微架构的并行度,二是采用多核架构。在微架构并行度一致的情况下,采用多核架构,可以减缓由于主频提高而功耗急剧上升的坡度,继续看下面的推导:
因为:处理器功耗 跟 电流 X 电压 X 电压 X 主频 成正比,IPC 跟 电流 成正比; 所以:处理器功耗 跟 IPC 成正比。
由上面的推导可以看出,提升IPC带来的功耗远远没有提高主频带来的那么高那么快!也就是说,达到相同的性能,多核处理器的功耗会比单核处理器低,如果功耗相同,毫无疑问多核处理器的性能会比单核处理器要高。这有效解决了靠一味提升主频来提升性能带来的功耗过高的问题,多核心技术必定是未来处理器发展的一个方向。
当然除了运用多核心技术,采用更加先进的高能效微架构也能提升处理器的性能,目前非常火的Intel酷睿架构的处理器就是一个现实中的例子。与上一代NetBurst微架构相比,酷睿架构就是提高IPC的创新技术
下面是在知乎上一位网友叫young cc的观点,说的很好,记录下来看一看
问:提高核心数和改善架构,这两种方案哪种更能提升 CPU 的性能?
解答:现在的任务都是多任务运行,多任务多线程就可以被多核并行执行,处理速度明显上升。另外单核已遇到瓶颈(上面的回答已经说得很好了),instrction prediction/prefetch, branch prediticon, out-of-order excution等做了这么多年,想提高已经很难了。想提升频率也很难,若增加流水线级数问题很多,hazards太多,设计验证都会很复杂,功耗太高。
多核不光是提高性能,一个很重要作用是降低频率降低功耗。功耗三次方于频率(电压正相关于频率),频率太高功耗就太高。举个例子, L5630 (4 Cores @ 2.13 GHz)是40瓦,而E5640 Xeon (4 cores @ 2.66 GHz)是95瓦。现在用多核并行处理,无须太高频率,无须太复杂单核设计,降低每个核研发难度,降低每个核功耗,以量取胜。随着摩尔定律发展,现在单个芯片集成的transistor都能billions级的,有这么多transistor就去堆核心呀,不然留着干嘛,transistor已经不值钱了。
多核要考虑到Amdahl's law 姆达尔定律_百度百科在多核基本是大核+小核 (异构多核),所以当有串行不可分割大任务就交给大核专注处理,其他的并行小任务交给其他核处理,处理速度明显上升。在异构多核中,有些任务就可以交给专用core(核心)专注处理,这样一些core就成变成ASIP(Application-specific instruction set processor,增加定制指令集),甚至ASIC,性能比通用CPU高上百倍。
题主说的 提升单核架构,不到万不得已不堆核。 真是站着说话不腰疼。单核做到极致的就那两家,你以为MTK,AMD不想么?但这哪是说想就能办到的,就算Intel也大概平均三年左右才升级一次架构,CPU性能提升的大头来自于工艺。堆多核比提升单核容易多了,他们当然选择最适合自己的。他们单核肯定也在做,只是单核提升真的很难,市场压力又这么大,当然优先选择堆多核这种简单粗暴见效快的,否则等他们单核做出突破时,黄花菜都凉了。Intel的多核也是相当牛了,64核,上百核的都有了。但消费者要求还没那么高,他们不急着放。
题主说提升cache,你是打算怎么提升呢?若增加容量,是能减少cache miss,但一次访问反而变慢,并且cache也很占area。至于提升总线速度,多核中直接用上NoC(片上网络),性能可比传统总线强。
在不同场景,不同公司根据自身条件都会制定不同策略,空谈哪种更合适没有意义。但多核是芯片设计的趋势,随着用户需求不断上升,per die上能集成的transistor不断增加,多核数量会越来越多
手机的多核不是为了忽悠消费者(也许也有这个因素),而是降低功耗(降低频率),提高性能,性价比最佳的解决方案。提高单核性能与发展多核是两 条腿走路,但现在单核已遇到瓶颈,而加多核效果显著,所以多核自然成了厂商最优选择。举个例子,3个2G的CPU比一个4G的CPU设计便宜多了。
系统的功耗是与频率成三次方关系增长(电压正相关于频率),而对于移动设备(电池供电)最大的问题就是功耗,所以注定手机的core(核心)的频率不能太高。但其实就是对于PC的单核性能也已经到达瓶颈了(详见我的回答 CPU搞大一点有用吗,为什么非要多核呢? - young cc 的回答)。所以就用一堆小核以较低的频率获得更好的性能。并且每个core都有自己的时钟域,这样可以通过DVFS,动态调整电压频率到合适值,降低功耗(详见核心速度不同对多核处理器性能有什么影响? - young cc 的回答)。另外单个RISC 的ARM的性能本身就比不过X86的CISC的CPU,所以更需要靠多核以数量取胜
问:Cpu搞大一点有用吗,为什么非要多核呢?
解答:原因是当前单核CPU的性能很难提升了,而用多核性能提升很明显,相对于单核性价比高。想想市场上能有几款4GHz的CPU,但集成多个2GHz 的multicore(多核)到处都是。
首先回答下,单核CPU如何提升性能呢?主要有提升工艺,添加Pipeline(流水线)去增加主频;Superscalar等,同时处理多条指令(instruction);或者Out-of-order执行指令,instruction prediction/prefetch等。讲下他们具体怎么实现,有哪些问题。
当主频提升,由于Power=,V(电压)又与f(频率)正相关,导致power基于f三次方上升。功耗会带来散热问题,也严重影响移动设备的续航能力。 工艺提升对power改善有限,并且也快达到临界电压了(每个transistor需要最低临界电压实现开关)。 对于Pipeline(流水线), 是不能无限分割。首先logic是不能无限分割的,并且每加一级pipeline,就需要增加register,增加了area,并且register读写也需要时间,导致一条指令从开始执行到结束的实际时间增加了。并且pipeline级数越多,越容易导致hazards,从而影响性能。
Superscalar是 issue multiple instructions per cycle。但当同时处理更多的instruction,需要考虑互相间的data dependency(数据相关性),使设计变得很复杂,性能提升有限。
微架构级的优化,如Out-of-order 执行指令, 当当前指令被stall,若后面的指令与他没有数据相关性,则可以先执行后面的指令;或者做指令预测,提前 读取/执行 指令,instruction prediction/prefetch。但当前这些已经做得不错,再想提升就得运用复杂的预测算法,性能提升有限。
通过以上可以看出,单核的提升有限,所以大家转到多核。
对于multicore,一切都变得简单,每个core可以设计的简单,并行处理数据。当前都是多个application并行运行,完美适合多核。比如同时处理图像,音频,跑APP,就交给几个core,每人处理一个。在多核系统中,通常有一个centralized core负责task scheduling,将task合理分配到各个core;每个core只处理简单的task,core的设计反而变得简单。在heterogeneous MPSoC(异构多核)中,有些specialized cores,只处理固定的application,从general processor成为了application-specific instruction set processor (ASIP),甚至能成为ASIC,使处理速度大幅上升(专用处理器比通用处理器性能优越)。
什么是核间通信开销
核间通信的主要目标是:充分利用硬件提供的机制,实现高效的CORE间通信;给需要CORE间通信的应用程序提供简洁高效的编程接口。 根据所使用的硬件特性,核间通信可能的实现机制有:
- Mailbox中断
- 基于共享内存的消息队列
- POW + Group
- FAU;支持原子的读,写,fetch and add操作
每个core有一个相应的32bit的mailbox寄存器,每一位可被单独地设置或清零。这对于core间的中断非常有用,任意core可直接通过其它core 的mailbox对其它core发出中断。当mailbox被置位时,相应core的中断寄存器也同时被置位,软件可实现其中断处理。
Bootloader支持Octeon_phy_mem_named_block_alloc( ),分配以名字命名的物理内存空间,不管是Service Executive应用程序还是linux kernel都可以通过Octeon_phy_mem_named_block_find( )找到这部分内存,实现core之间的共享数据。
Linux kernel也提供了共享内存的机制。主要有mmap(),系统V,Posix共享内存模型等。系统调用mmap()通过映射一个普通文件实现共享内存。普通文件被映射到进程地址空间后,进程可以向访问普通内存一样对文件进行访问。系统V共享内存指的是把所有共享数据放在共享内存区域(IPC shared memory region),任何想要访问该数据的进程都必须在本进程的地址空间新增一块内存区域,用来映射存放共享数据的物理内存页面。posix共享内存区首先指定一个名字参数调用shm_open,以创建一个新的共享内存区对象或打开一个以存在的共享内存区对象。然后调用mmap把这个共享内存区映射到调用进程的地址空间。传递给shm_open的名字参数随后由希望共享该内存区的任何其他进程使用。
核间通信开销:多核处理器在嵌入式领域得到越来越广泛的应用,在多核环境下,运行在不同核上的任务之间存在数据依赖,即多核之间存在数据共享问题,一致性缺失问题便由此产生,Uppsala大学14年一篇IEEE论文提出,在有些情况下14' IEEE,一致性缺失事件发生造成的开销基本等于多核性能损失的那部分加速比,当然这是在程序并行度理想的情况下,因为影响多核加速比的另一个重要因素是程序的并行度的高与低。
为了引出一致性缺失与核间通信开销的关系,我需要引用下面几篇论文的实验和结论
1.下面详细说明下上面提到的这一篇文章中提到的观点:在文章的Introduction的第二段,我这里将他翻译一下吧:
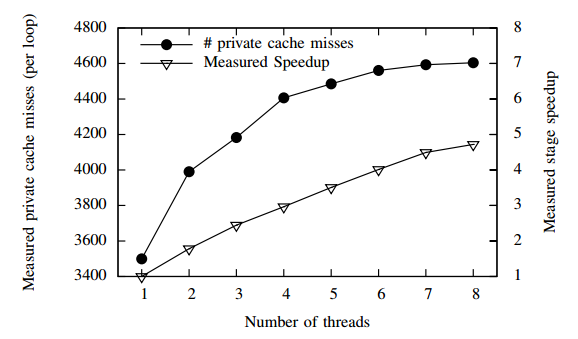
为了说明一致性缺失会导致多核性能降低,请看PARSEC benchmark的dedup测试集的"Deduplication"阶段的理论分析与实验结果。在这个阶段,并行的线程同时处理大量的数据块。在处理每个数据块的执行期间,线程访问一个全局的哈希表。下图是表明随着线程数
从1到8的增加,包括L1,L2(这篇文章讨论的是X86架构,我们知道X86共三层cache,前两层私有,L3共享,而ARM架构只有2层Cache结构,L1私有,L2公有)两层私有Cache的miss次数。实验数据是将每个线程固定到不同的core上,也就是每个core上至多一个线程。实验结果显示开8个线程在8个核上运行比开1个线程在一个核上运行平均每个私有cache上的miss次数增加34%。而这部分多出来的cache miss主要来自于对临界区共享数据的访问,因为保护共享数据而导致这段临界区的执行时间增加了30%。增加的临界区执行时间导致更糟糕的性能损失影响,包括增加了等待获取数据锁的时间。最终的结果就是实际获得的并行阶段的加速比远没有随着线程数线性化增加。
实际获得的这个阶段8个线程的加速比是4.72。如果没有一致性缺失,在临界区的执行时间就不会增加,从而避免更糟糕的性能所示影响。根据一个更加细节的计算,得出的结论是,如果没有一致性缺失事件的发生,那么8个线程在这个阶段的加速比为7.5。所以说这个阶段的加速比的损失基本全部来自于一致性缺失的贡献。
2.2015年一篇Trans期刊,论文名叫《Adaptive Cache Coherence Mechanisms with Producer-Consumer Sharing Optimization for Chip Multiprocessors》一文中有这么两句话对我论文很重要,因为这句话是我要在我的论文中引用的,表明我主要研究cache一致性缺失对核间通信开销的影响,因为它是多核性能开销的一个主要原因,所以贴出来,记一下。
1.In Chip Multiprocessors(CMPs),maintaining cache coherence can account for a major performance overhead.
2.The proposed mechanisms were shown to reduce coherence misses by up to 48% and in return speed up application up to 30%
翻译一下:
1.在多核处理器中,保持Cache的一致性可以算是性能开销的一个主要原因
2.提出的机制实验显示可以减少48%的一致性缺失,换得的是应用运行加速了30%
3.07年一篇合肥工业大学的硕士论文《对称多核处理器中cache一致性的研究与实现》的摘要第一段有这么样一句话:在此基础上引出了数据一致性问题,数据高速缓存的一致性(cache coherence)是解决多核之间通信的一个重要课题
4.11年一篇哈尔滨工程大学的硕士论文《多核环境Cache一致性协议研究》的摘要也有类似的一句话:多核处理器与单核处理器相比具有容易获得高频率,功耗低,通信延迟等优点,但是同样存在着应用限制和技术挑战,其中,Cache一致性是影响多核处理器性能的一个关键问题
5.10年一篇来自于ACM的论文《An adaptive cache coherence protocal for chip multiprocessors》摘要的第二句话如下:
CMPs(Chip Multiprocessors) introduce many challenges that need to be addressed to achieve the best performance. One of the big challenges comes with the shared-memory model observed in such architectures which is the cache coherence overhead problem.
翻译一下:
为了获得最好的性能,多核处理器引入了很多挑战。这其中有个很大的挑战来自于共享内存处理器架构的一致性开销问题。
由此可见一致性缺失确实是现在多核核间通信开销的一个问题。
核间通信不可避免,而不可避免的多核间核间通信开销又阻碍了系统性能大幅提升,使得多核性能不能随着核数的增加而线性增加,因此研究如何降低核间通信开销 变得尤为重要。而本文研究重点是快速并有效的量化不同cache配置下核间通信开销(其实就是一致性缺失惩罚时间)。
顺便提一下,多核操作系统需要面临的两大难题
- 如何让应用并行化以获得效率,所谓的并行度高
- 如何对资源合理分配以达到性能最优,减少对资源的竞争,降低一致性缺失事件发生的次数。
核间通信开销与多核性能的关系
多核性能的非线性化包含核间通信开销因素,12年一篇Ghent大学的论文说到了加速比栈,也就是加速比跟哪些因素有关,请看下图
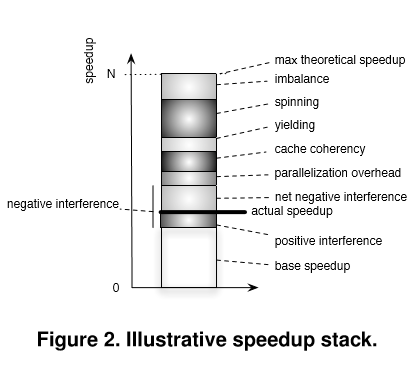
可以看到多核加速比跟很多关系相关,包括并行化开销,cache一致性等很多因素,但是核间通信开销主要还是跟一致性缺失相关。
综上,有了这些材料,可以写论文第一章了。